
Rice course - intro to database
Early Open Source Databases
- Postgres (1997) / PostgreSQL
- MySQL (1995)
- SQLite (2000)
POSTGRES, the predecessor to PostgreSQL, was created first in 1986 at UC Berkeley. Its name was short for “POST-Ingres”, as it was a successor to the Ingres database. The original system did not use SQL, but support was added around 1995, and soon after, it was renamed to PostgreSQL. Many experienced developers prefer Postgres because it has a superior query optimizer, more advanced data types, is less likely to produce unexpected results and deadlocks.
MySQL was created in 1995 by Michael Widenius and David Axmark as an alternative to the mSQL database. The system was named after Michael’s daughter, My. From the start, the database was designed to be flexible, powerful, and relatively easy to use. This led to its quick adoption by the web hosting community, and it was used as the default database for WordPress. MariaDB (named after Michael’s other daughter, Maria) was initially created as a drop-in replacement for MySQL.
SQLite is a serverless database engine. It functions as a lightweight library embedded directly into applications, reading and writing data from a single file on disk. This simplicity eliminates the need for a separate server process and makes SQLite highly portable. However, SQLite’s concurrency model is more restrictive: while it allows multiple readers, only one process can write to the database at a time. (If you have a Mac, sqlite3 should be available on there.)
The Relational Model is usually denoted using LIKES (DRINKER, COFFEE)
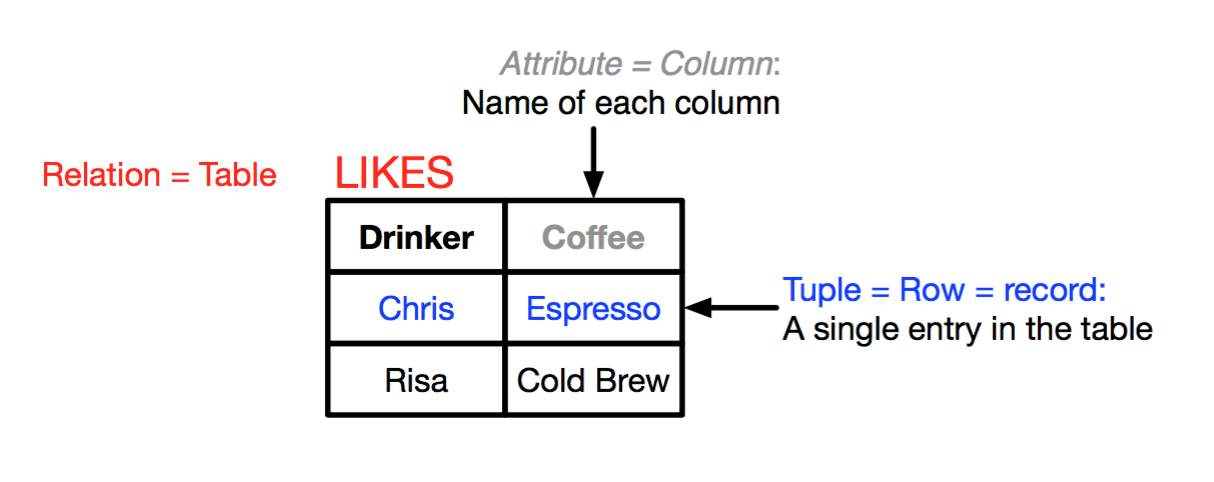
Keys (If the key for two tuples are the same, they must be the same tuple)
- Candidate Keys: A relation schema can have many keys, those that are minimal are CANDIDATE KEYs.
- Primary Keys: One minimal CANDIDATE KEY is typically designated as the PRIMARY KEY.
- Foreign Keys: we still need some notion of between-tuple references.
Super key: An attribute or set of attributes that uniquely defines a tuple within a relation. However, a superkey may contain additional attributes that are not necessary for unique identification.
The foreign key must be an attribute or set of attributes that are uniquely identify a record in another table, and that combination of attribute values must be present in the other table.
Attribute Constraints
- DEFAULT, NULL/NOT NULL, UNIQUE, CHECK
Table Level Constraints
- PRIMARY KEY, FOREIGN KEY, UNIQUE, CHECK
PRIMARY KEY Constraint
- Enforces uniqueness when the attribute is populated
- Creates an index
- Disallows NULLs
- Can be compound or single attribute
- Can be natural (LastName, FirstName, DOB)
- Can be synthetic (assigned by the database)
Relational Algebra
- Projection π: Projection removes attributes
- Selection σ: Selection removes tuples
- Rename ρ: Renames attribute or relation
- Assignment ←: For convenience, assigns the relation to a temporary variable
- Join: Cartesian product (aka: cross product),Theta Join,Natural Join
- Union, Intersection, Difference
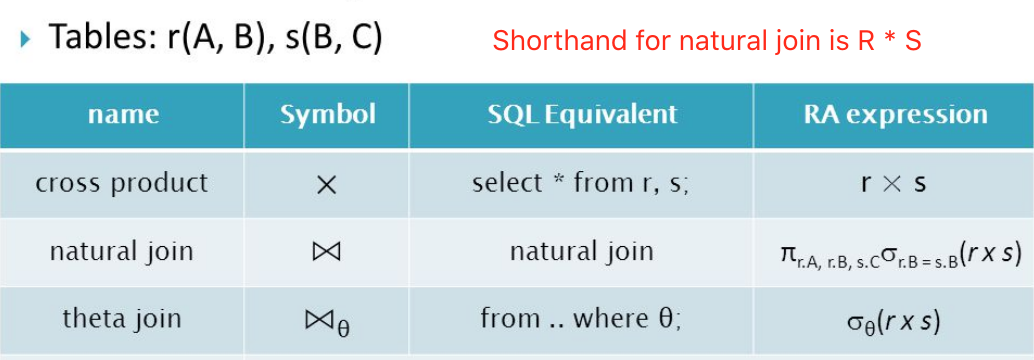
Left / Right Outer Join
- R LEFT OUTER JOIN S ON
R.<att> = S.<att>- LEFT JOIN and LEFT OUTER JOIN are the same
- 包括左表中的所有行以及右表中匹配的行,如果左表的某行在右表中没有匹配行,assigns NULLs
SQL
- Data Manipulation Language (SELECT, INSERT, UPDATE, DELETE…)
- Data Definition Language (CREATE, ALTER, DROP…)
- Data Control Language (GRANT, REVOKE…)
-- Who goes to a cafe serving Cold Brew?
SELECT DISTINCT f.DRINKER
FROM FREQUENTS AS f, SERVES AS s
WHERE f.CAFE = s.CAFE AND s.COFFEE = 'Cold Brew'WHERE Clause
- <Attribute> = <value>
- <Attribute> BETWEEEN <value1> AND <value2>
- <Attribute> IN ([value1], [value2], ?)
- <Attribute> LIKE 'SST%'
- <Attribute> LIKE 'SST_'
- <Attribute> IS NULL
- <Attribute> IS NOT NULL
- Logical combinations with AND and OR
- We can also have a subquery in the WHERE clause (EXISTS / NOT EXISTS, IN / NOT IN )
/*
% represents zero, one or multiple characters
- represents a single character
*/-- Who goes to a cafe serving Cold Brew?
SELECT DISTINCT f.DRINKER
FROM FREQUENTS AS f
WHERE EXISTS (
SELECT s.CAFE
FROM SERVES AS s
WHERE f.CAFE = s.CAFE AND s.COFFEE = 'Cold Brew'
)
/*
f 的每一行带入子查询,检查返回结果是否为 true
EXISTS 用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回 True/False
*/Aggregations and Grouping
In database management, an aggregate function is a function where the values of multiple rows are grouped together to form a single value of more significant meaning.
- SUM, AVG, COUNT, MAX, MIN
SELECT r.COFFEE, AVG (r.SCORE)
FROM RATES AS r
GROUP BY r.COFFEE- Groups the relation into subgroups, every tuple in the subgroup has the same value for
r.COFFEE, then the aggregate runs over each subgroup independently. - If you have an attribute outside of an aggregate function in an aggregate query, then you must have grouped by that attribute, or the query will not compile.
- The power of aggregate functions is greater when combined with the GROUP BY clause. The GROUP BY clause is rarely used without an aggregate function. (If you use GROUP BY with no aggregate functions in the select, you are just doing a DISTINCT.)
SELECT r.COFFEE, AVG (r.SCORE) AS AVG_RATING
FROM RATES AS r
GROUP BY r.COFFEE
HAVING COUNT(*) >= 3HAVINGis used to filter groups.HAVINGis applied after the group by phase whereasWHEREis applied before the group by phase.
What about NULL?
COUNT(1)orCOUNT(*)will count every row.COUNT(<attribute>)will count NOT NULL values.- AVG, MIN, MAX, etc. ignore NULL values.
GROUP BYincludes a row for NULL.
count(1)是在统计个数,可以想成表中有这么一个字段,这个字段就是固定值1,计算一共有多少个1。同理,count(2),count('x')都是可以的。
CREATE TABLE
CREATE TABLE Student (
netId varchar(15) NOT NULL,
lastName varchar(100) NOT NULL,
firstName varchar(100) NOT NULL,
dateofbirth DATE NULL,
PRIMARY KEY (netId)
);- Tables are often named by singular nouns.
- Table and attribute names are usually case-insensitive.
- Key constraints are typically specified after all attributes.
- Semicolons are used to separate SQL statements.
DROP TABLE
DROP TABLE [IF EXISTS] <tableName>;- What happens if you try to drop a table that has foreign key references (other tables reference it)? You must drop the constraint before you can drop the table. Otherwise it’s a rule violation.
ALTER TABLE
- Add / delete columns
- Rename table / columns
- Add / delete constraints
- Change column data type
- Change keys
Populating Tables
INSERT INTO Room (classroomId, building, abbrev, room) VALUES
('DCH1070', 'Duncan Hall', 'DCH', '1070'),
('DCH1055', 'Duncan Hall', 'DCH', '1055'),
('HRZ211', 'Herzstein Hall', 'HRZ', '211'),- The columns for which the values are not provided are filled by
null, which is the default values for those columns. - If you omit the list of columns (只写 table,不写 attribute), you must supply values for all columns.
Update and Delete
UPDATE <tableName> SET <attribute> = <value> WHERE <condition>;DELETE FROM <tableName> WHERE <condition>;
Entity-Relationship Diagram (ERD)
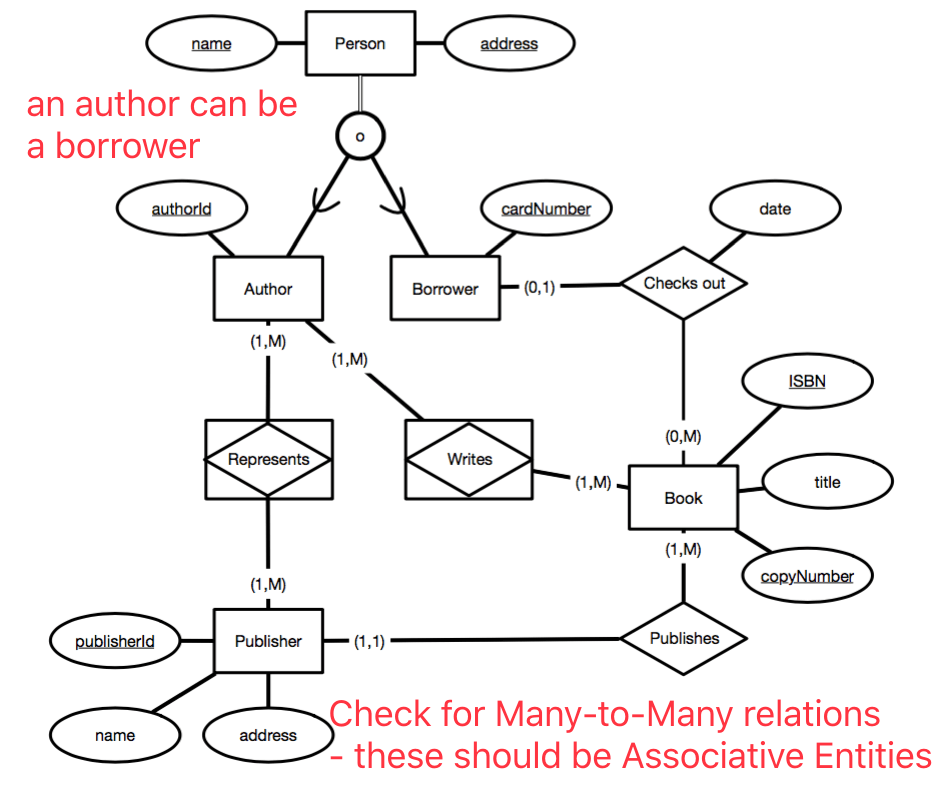
(a, b)表示参与关系的最少数量和最多数量- Associative Entities are used to represent Many-to-Many relations, basically a relation made up of primary keys. Typically implemented as a table.
From ERD to Tables
- Whenever you have a relationship, whether it be associative or not, you need to include that relationship in your database.
- Simple attributes go into the entity. Complex attributes can become (weak) entities with foreign key references back to the parent entity.
- Each entity
1-1: Foreign key for one of the entities to the other1-M: Foreign key in M side referencing the 1 side
- Each
M-Mrelationship - Each self-referential relationship
- Each subclass entity, add a foreign key that refers to the superclass
Data Normalization
- To prevent anomalies
- Based on the idea of functional dependencies
- Ensure that every non-key column in every table is directly on exactly the key
- Levels 1-3 are commonly used
1st normal form
- Each row / column contains a single, atomic value
- No attribute has more than 1 value for each relation
- Addresses the “shape” of a tuple

2nd normal form
- 1st Normal Form +
- Every non-key attribute is functionally dependent on the entire key
- Addresses the relationships between key and non-key fields

3rd normal form
- 2nd Normal Form +
- No non-key attribute depends on another non-key attribute
BCNF
- BCNF is an advanced version of the third normal form, and it is also known as the 3.5 Normal Form.
- 3rd Normal Form +
- X should be a superkey for every nontrivial functional dependency X -> Y
Thoughts on normalization
- Don’t be afraid of having a lot of tables with just a few columns
- 3rd Normal Form is usually good enough
- Consider denormalization for performance reasons (introduces more tables which leads to more joins)
SQL Injection Attack
-- UserId: 105 OR 1=1
SELECT * FROM Users WHERE UserId = 105 OR 1=1;
-- UserId: 105; DROP TABLE Suppliers
SELECT * FROM Users WHERE UserId = 105; DROP TABLE Suppliers;
-- uName: " or ""="
-- uPass: " or ""="
-- sql = 'SELECT * FROM Users WHERE Name ="' + uName + '" AND Pass ="' + uPass + '"'
SELECT * FROM Users WHERE Name ="" or ""="" AND Pass ="" or ""=""Indexing
B+ Tree is the most common type of storage for RDBMSs
- Designed for accessing data on disk
- internal node and leaf nodes
An index is a structure like the one at the end of a book. At the end of a book you see several pages with words and where you can find those words. Those pages are an index and the same is the case for a database. The index contains key and their locations. It helps you finding the location of rows.
- Composed of (key, ptr) pairs. Mapping a key value to a disk location
- Search Key: Attribute or set of attributes used to look up records
Transaction
Group of operations performed together, follow the ACID properties
- Atomicity: All or nothing
- Consistency: Database is always in a valid state
- Isolation: Each transaction appears to have executed as the sole user of the database
- Durability: Once a transaction completes successfully, its changes are permanent
START TRANSACTION;
SELECT balance FROM checking WHERE customer_id = 1;
UPDATE checking SET balance = balance - 100 WHERE customer_id = 1;
UPDATE savings SET balance = balance + 100 WHERE customer_id = 1;
COMMIT;允许在一个事务中的操作语句会被其他事务的语句隔离开,比如事务 A 运行到第 3 行之后,第 4 行之前,此时事务 B 去查询 checking 余额时,仍然能够看到在事务 A 中减去 100 之前的余额,因为事务 A 和 B 是彼此隔离的。在事务 A 提交之前,事务 B 观察不到数据的改变。
- 用户 1 的操作执行完,再执行用户 2 的操作,将一组操作组成一个事务,事务中进行封锁,保证事务的可串行性。
- 调度 scheduling: 是指对一组可能来自多个不同事务操作流的一种序列安排。
- 串行的 (serial): 如果在一个调度中,属于同一个事务的指令紧挨在一起 (no overlap between transactions),我们就称这个调度是串行的。
- 可串行化的 (Serializable): 几个事务并行执行是正确的,当且仅当其结果与某一次序串行执行它们的结果相同。
Isolation Level
Dirty data: data written by a transaction that has not been committed
- dirty read: T2 修改了一行数据,然后 T1 在 T2 还未提交修改操作之前读取了被修改的行。此时如果 T2 回滚了修改操作,那么 T1 读取的数据就是是从未存在过的。
- non-repeatable read: 当事务两次读取同一行数据,但两次得到的数据都不一样,比如 T1 读取一行数据,然后 T2 修改或删除该行并提交修改操作。当 T1 试图重新读取该行时,它就会得到不同的数据或发现该行不再存在。
- phantom read: 一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,比如 T1 读取满足某种搜索条件的一些行,然后 T2 插入了符合搜索条件的一个新行。如果 T1 重新执行查询,就会得到不同的行。
SET TRANSACTION ISOLATION LEVEL
- READ UNCOMMITTED,可读取未提交数据,比如 T1 没有 commit,T2 依然能读到 T1 的修改,这是所有隔离级别中最低的一种,会出现脏读。
- READ COMMITTED,只能读取到其他事务提交的数据,未提交的数据读不到(PostgreSQL 默认的隔离级别),这样的问题是non-repeatable read,事务 A 先读取了数据,此时事务 B 更新并提交了数据,而事务 A 再次读取该数据时,数据已经发生了改变,出现不可重复读。
- REPEATABLE READ,可以重复读,每次读取的数据结果都相同(MySQL 默认的隔离级别),事务在读取的过程中会对数据增加行级共享锁,直到事务提交才会释放锁,所以在这段时间内,该事务无论读取该行数据多少次,结果都一样。它的问题是 phantom read,在事务 A 的两次查询之间,事务 B 向表中插入一条数据,此时没有任何事务对表增加表级锁,可以顺利插入,此时事务 A 第二次的查询结果就会和第一次不一样,出现幻读。
- SERIALIZABLE,其他事务对该表的写操作将被挂起,这是隔离级别中最严格的。范围锁,Prevents other transactions from inserting tuples until this transaction completes. 隔离级别越高,执行效率就越低,像 Serializable 这样的级别,就是锁表的方式,使得其他线程只能在锁外等待。
- READ UNCOMMITTED
- No locks
- READ COMMITTED
- Read locks released when no longer needed
- Write locks held until transaction ends
- No range locks
- REPEATABLE READ
- Read and Write locks held until transaction ends
- No range locks
- SERIALIZABLE
- Read and Write locks held until transaction ends
- Range locks
How can we deal with failures? —Logs
undo 日志用于记录事务开始前的状态,用于事务失败时的回滚操作;redo 日志记录事务执行后的状态,用来恢复未写入 data file 的已成功事务更新的数据。例如某一事务 T1,其对数据 X 进行修改,设 X 的原值是 5,修改后的值为 15,那么 Undo 日志为 <T1, X, 5>,Redo 日志为 <T1, X, 15>.
redo 日志
当数据库对数据做修改的时候,需要把数据所在的 page 从磁盘读到 buffer pool 中,然后在 buffer pool 中进行修改,这时候 buffer 中的数据页就与磁盘上的数据页内容不一致(脏页),此时的数据尚在缓存中还没有持久化,如果 DB 出现故障就会导致丢失数据,因此,Innodb 会在 buffer pool 中的 data page 变更结束后,将相应的修改记录到 redo log 里进行持久化。redo log 记录某数据块被修改后的值,可以用来恢复未刷新到磁盘上的数据,并且总是日志先行,它先于脏页刷新到磁盘上。(在持久化数据文件前,保证之前的 redo 日志已经写到磁盘 flush the log to disk)
NoSQL
To address the need for storage of non-relational data
- Key-value stores (MemcacheDB)
- Document stores (MongoDB)
- Graph stores (Neo4J)
- Column stores
SQL -> MongoDB
- table -> collection
- Grouping of documents
- Document schemas do not have to be consistent
- row -> document
- Set of key-value pairs
- May contain nested documents
- Keys do not have to be the same in all documents within a collection
- column -> field
